- 캐시 메모리 시리즈 모아보기 -
https://microelectronics.tistory.com/102
Cache의 작동 원리
1. Cache 개요
Cache는 연관 기억 장치(associative memory)로, 단순히 메모리 주소로 데이터를 찾는 것이 아니라, 특정 데이터가 담긴 "위치 정보"를 기준으로 데이터를 저장하고 찾을 수 있게 한다.
2. Cache의 구성 요소

- 태그 (Tags): 태그는 메모리 위치의 주소를 의미한다. 예를 들어, 메모리 위치 8에 있는 명령어를 Cache에 넣으면 태그 8이 Cache에 저장되며, 이는 해당 데이터의 메모리 위치를 참조한다. Cache의 나머지 부분에는 실제 데이터가 저장된다. 당연히 'full address' = 'tag' 가 아니다. tag는 full address 의 일부일 뿐이다. 이에 대한 내용은 본문 아래 다음 챕터에서 다룬다.
- 데이터 (Data): Cache에 저장된 메모리의 실제 데이터로, 빠르게 접근하기 위한 정보이다.
- 유효 비트 (Valid Bits): Cache의 데이터가 유효한지, 즉 접근 가능한지를 나타내는 비트이다. 컴퓨터가 처음 켜질 때 Cache에는 0이나 무작위 데이터가 채워져 있을 수 있다. 유효 비트는 데이터가 유효할 때 1로 설정되고, 그렇지 않을 때는 0으로 설정된다. 컴퓨터가 시작될 때, 프로그램이 전환 될 때, 컴퓨터가 절전모드로 들어갈 때 모든 유효 비트는 0으로 설정되어야 한다. 즉 cache 의 모든 데이터는 무효화 된다.
3. 데이터 저장 과정 예시
- CPU는 메모리에서 데이터(예: 주소 8)를 불러오고, 이 주소를 태그로 설정하여 Cache에 저장한다.
- DRAM으로부터 데이터를 받아 Cache에 데이터와 태그를 함께 저장한다.
- 유효 비트를 1로 설정하여 이후 접근 시 이 데이터가 유효함을 나타낸다.
4. Cache에서 데이터 접근
- CPU는 접근하려는 주소(예: 8)를 Cache에서 확인하고, 해당 태그가 Cache에 있는지 확인한다.
- 태그가 존재하고 유효 비트(Valid bit)가 1로 설정되어 있으면, Cache에서 데이터를 바로 CPU로 불러온다. 이렇게 하면 메인 메모리에 접근할 필요가 없어 속도가 빨라진다.
- 만약, 유효 비트가 0이면 Cache의 데이터가 유효하지 않음을 의미한다. 이때는 DRAM에서 데이터를 불러와 Cache에 저장하고 유효 비트를 1로 설정한다.
캐시 블록(캐시 라인)
데이터 저장 효율성을 높이기 위해 캐시에서 데이터를 큰 덩어리로 저장하는 방식을 살펴본다.
1. 캐시 효율성
캐시에 저장된 데이터가 있는지 확인하려면, 모든 캐시 엔트리를 하나씩 검색하거나 한 번에 검색할 수 있다.
그러나 많은 캐시 엔트리를 일일이 검색하기에는 시간이 오래 걸리므로, 빠르게 검색하기 위해 한 번에 모든 엔트리를 검색할 필요가 있다.
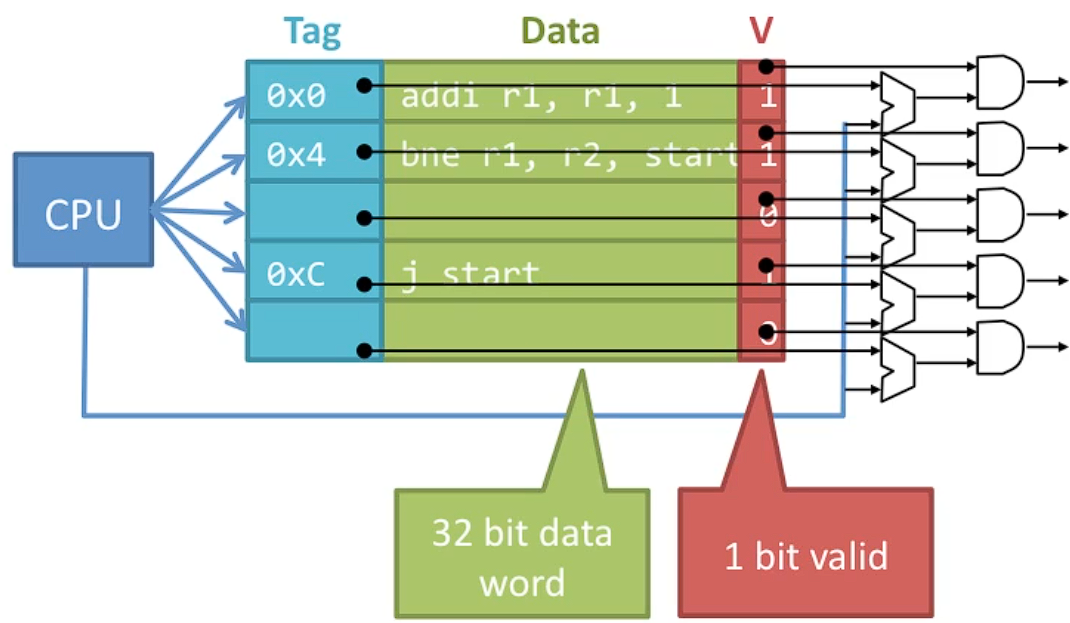
이 경우, 각 캐시 엔트리에 대해 주소를 비교할 비교기를 준비하고, 유효 비트(valid bit)를 확인할 AND 게이트가 필요하다. 하지만 비교기와 AND 게이트가 많아지면 하드웨어 비용이 증가하므로, 캐시 전체를 동시에 검색하기 위한 논리 비용이 높아지게 된다.
1.1 태그와 메모리 효율성
별다른 방법을 사용하지 않고 정직하게 32bit 캐시라인의 캐시를 구성하면,
각 캐시 엔트리는 데이터(32비트), 유효 비트(1비트), 주소 태그(30비트)로 구성되며, 총 63비트가 필요하다.
(4바이트 data라 주소 하위 2비트는 항상 0이기 때문에 태그는 30비트이다.)
그러나 이 중 실제 데이터를 저장하는 비트는 32비트에 불과해, 절반 정도가 태그 정보로 인해 낭비된다. 태그 공간을 줄이기 위해, 데이터 덩어리(block)를 더 큰 단위로 관리하면 더 적은 태그를 사용해 효율성을 높일 수 있다.
1.2 태그 공간 문제 해결

캐시 블록을 하나의 word가 아닌 두 개, 네 개, 혹은 16개로 확장하여 단일 태그에 더 많은 데이터를 포함시키면 태그 비율이 감소해 저장 공간 효율이 높아진다. 예를 들어, 두 word를 하나의 블록으로 사용하면 캐시 낭비는 대략 1/3로 줄고, 네 word 블록으로 확장하면 대략 1/5로 줄어든다.
이처럼 더 큰 데이터 블록을 사용하면 필요한 태그 수가 줄어들어 공간 효율성을 높일 수 있다. 현대 프로세서는 이러한 방식으로 캐시를 운영하며, 캐시 블록(라인)은 데이터의 최소 저장 단위로 활용된다. (캐시 라인과 캐시 블록은 같은 의미로 사용된다.)
2. 캐시에서 데이터 접근 방법

여러 word가 포함된 캐시 블록에서 데이터를 접근할 때는 주소와 태그를 확인하고, 유효 비트를 검사한 후 원하는 word를 읽어낸다. 구체적으로는, 데이터 블록 안에서 특정 word를 선택하기 위해, 멀티플렉서(MUX)를 통해 선택된 데이터를 CPU에 전달한다.
위 그림과 같이 주소의 비트 중 일부는 캐시 블록 내 word 선택에 사용되며, 일부는 바이트 선택에 사용된다. 블록 태그와 word, byte 비트를 통해 필요한 데이터를 정확히 식별할 수 있다.
3. 캐시 블록 크기
3.1 Line Size 와 주소 비트 길이

각 캐시 블록에 저장되는 단어 수에 따라 주소 비트 사용 방식이 달라진다. 예를 들어, 단일 word 블록은 태그에 30비트, 바이트 선택에 2비트를 사용한다. 반면 2 word 블록은 태그에 29비트, word 선택에 1비트, byte 선택에 2비트를 사용하며, 네 word 블록은 태그에 28비트, word 선택에 2비트, byte 선택에 2비트를 사용한다.
3.2 캐시 블록 크기의 효율성: 사례 연구
블록 크기가 큰 캐시는 여러 인스트럭션을 한 번에 불러오기 때문에, 이후의 명령어에 대해 추가적인 로딩 없이 바로 사용 가능하다. 이는 데이터의 공간적 지역성(spatial locality)을 이용한 것으로, 접근한 데이터 주변의 데이터도 함께 로드해 성능을 향상시킨다.
예를 들어, 4개의 word를 블록으로 관리하는 경우, 필요한 명령어 외에 이후 명령어들을 미리 가져와 실행 효율성을 높일 수 있다.
3.3 큰 캐시 블록의 장점과 단점
큰 캐시 블록은 태그 공간 낭비를 줄이고, 데이터를 더 많이 로드해 성능을 향상시킨다. 그러나 모든 데이터를 사용하지 않으면 공간 낭비가 발생할 수 있다. 예를 들어, 4word 블록에서 짝수 인덱스만 참조하는 코드가 있을 때, 절반의 데이터는 사용되지 않아 낭비된다.
그럼에도 불구하고 대부분의 현대 프로세서는 표준 캐시 라인 크기로 64바이트를 사용하며, Intel 기반 머신에서는 64바이트 캐시 라인을 한 번에 두 개씩 가져와 효율성을 높인다.
결론
현대 캐시 설계는 데이터를 효율적으로 저장하기 위해 더 큰 블록 단위로 데이터를 저장하고, 각 블록에 하나의 태그를 사용하여 공간 효율성을 극대화한다. 이러한 설계는 공간적 지역성을 활용하여 데이터 접근 속도를 향상시키지만, 상황에 따라 일부 데이터가 낭비될 수 있는 단점도 존재한다.
Reference
'Computer Architecture > Virtual Address & Cache' 카테고리의 다른 글
| 캐시 메모리 교체 정책 Overview (0) | 2024.11.04 |
|---|---|
| Fully-Associative vs Direct-Mapped vs Set-Associative Cache (0) | 2024.11.03 |
| 메모리 계층 구조(Memory Hierarchy)와 캐시 (0) | 2024.11.01 |
| 가상 메모리 시리즈 요약 (0) | 2024.10.31 |
| MMU(Memory Management Unit)와 캐시 메모리 (0) | 2024.10.30 |




댓글