- 프로세서 시리즈 모아보기 -
https://microelectronics.tistory.com/112
기본적인 ISA 동작 방식을 모르면 이해하기 어렵습니다.
Pipeline
1. 프로세서 파이프라이닝의 필요성
1.1 단일 사이클 프로세서

단일 사이클 프로세서는 모든 명령어를 한 사이클 내에 실행하는 방식으로 설계된다. 이 방식은 간단하지만, 각 명령어의 실행 시간이 다르기 때문에 문제가 발생한다. 가장 시간이 오래 걸리는 경로(critical path) (예: load 명령어)로 인해 전체 사이클 시간이 결정되고, 이는 프로세서 속도를 제한하게 된다. 예를 들어, 프로그램에서 load와 store 명령어가 30%를 차지하고, 이 명령어들의 실행 시간이 두 배로 길다면, 전체 시간의 35%가 낭비되는 셈이다.
1.2 멀티 사이클 프로세서

이 비효율을 해결하기 위해 멀티 사이클 프로세서가 도입되었다. 멀티 사이클 프로세서는 명령어마다 서로 다른 사이클 수를 가지며, 속도가 빠른 명령어에 맞춰 클럭을 설정하고, 느린 명령어만 추가 사이클을 할당받는다. 결과적으로 단일 사이클보다 효율적으로 작동하지만, 각 명령어의 사이클 수와 그 단계에서 수행할 작업을 관리하는 데 복잡성이 증가한다.
2. 파이프라인의 기본 개념
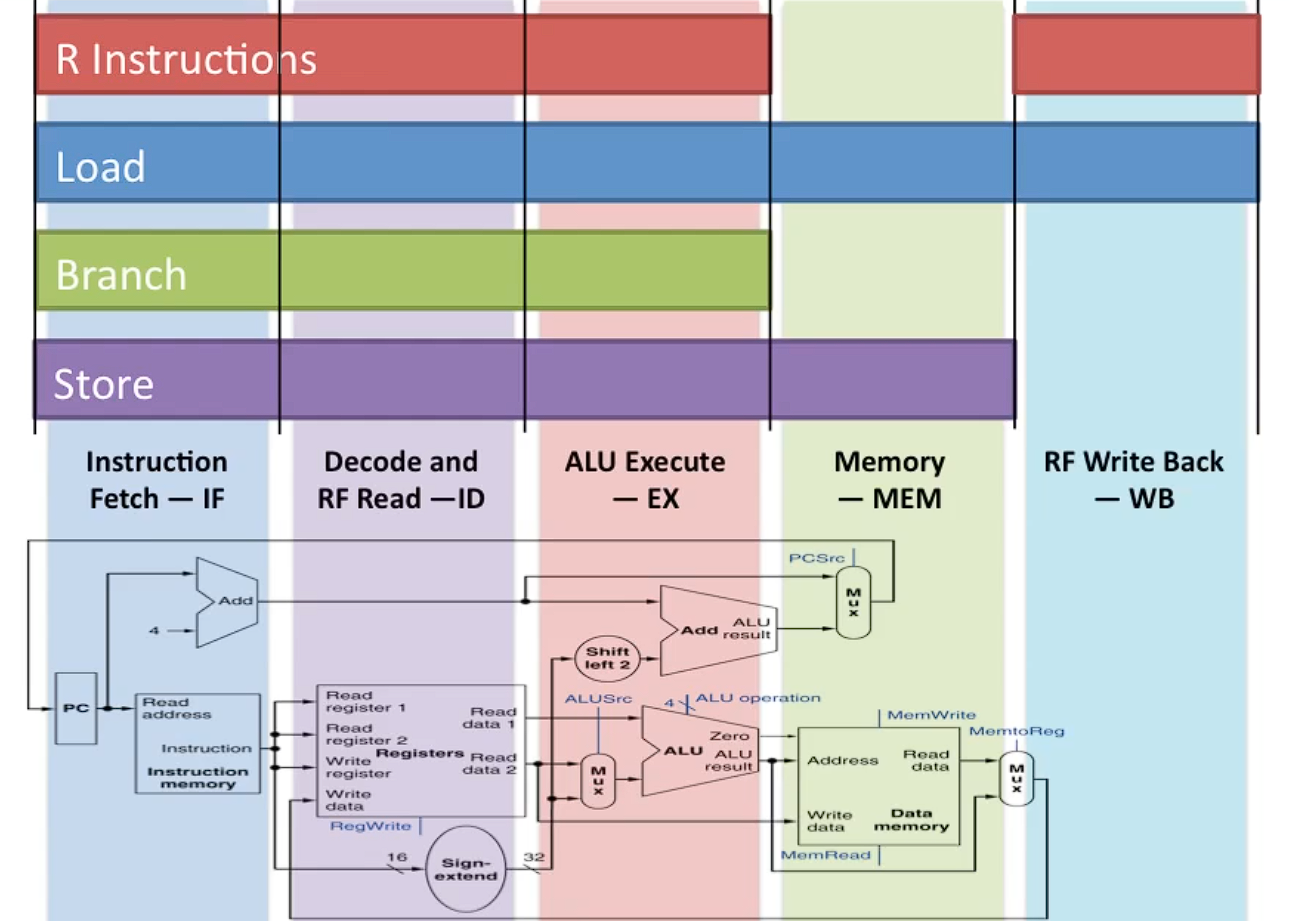
파이프라이닝은 단일 및 멀티 사이클의 단점을 극복하기 위한 기술로, 명령어를 여러 단계로 나누어 각 단계에서 서로 다른 명령어를 동시에 실행하는 방식이다. 파이프라인은 5단계 (Fetch, Decode, Execute, Memory Access, Write-back)로 구성되며, 모든 명령어는 이 동일한 단계를 거친다. 이렇게 각 단계는 독립적으로 실행되며, 여러 명령어가 서로 다른 단계에서 동시에 처리될 수 있다.
3. 파이프라인 실행 예시

- 첫 번째 명령어가 Fetch 단계에 있을 때, 두 번째 명령어는 그 다음 사이클에서 Fetch 단계에 진입하고, 첫 번째 명령어는 Decode 단계로 넘어간다.
- 각 명령어가 다른 파이프라인 단계에 위치하여 동시에 여러 명령어가 실행된다.
- 사이클 3에서 로드 명령어는 ALU에서 주소를 계산하고, R 형식 명령어는 Decode를, 저장 명령어는 Fetch를 수행한다.
- 이처럼 각 사이클마다 서로 다른 명령어들이 동시에 다른 파이프라인 단계에서 작업을 수행한다.
4. 파이프라이닝의 장점
- 성능 향상: 명령어들이 동시에 여러 단계에서 처리됨으로써 프로세서의 자원을 보다 효율적으로 사용한다.
- 병렬 처리: 여러 명령어가 서로 다른 단계를 거치며 동시에 실행되어 처리량이 증가한다.
5. 실생활에서의 예시

파이프라이닝을 이해하기 위해 세탁을 예로 들어보자. 세탁을 하기 위해서는 세탁, 건조, 접기, 옷장에 정리의 네 가지 단계를 거쳐야 하며, 각각의 단계는 한 시간이 걸린다고 가정한다. 만약 네 번의 세탁을 순차적으로 처리한다면, 한 번에 한 작업씩 해야 하므로 16시간이 소요된다. 첫 번째 세탁을 시작해 세탁이 끝난 후 건조하고, 이후 접고 정리하는 방식으로 각 로드를 연속 처리하는 방식이다.
하지만 파이프라이닝을 적용하면 더 효율적으로 할 수 있다.
첫 번째 로드를 세탁하고 나면 세탁기가 비게 되므로,
두 번째 로드를 바로 세탁기에 넣고 첫 번째 로드는 건조기에 넘긴다.
이렇게 작업이 겹치도록 처리하면 네 번의 세탁을 총 7시간 만에 완료할 수 있다. 각 로드는 여전히 4시간이 걸리지만, 전체 작업 시간이 대폭 줄어드는 것이다. 즉, 다른말로 처리량(throughput)은 증가하지만, 지연시간(latency)은 변하지 않는다.
6. 파이프라이닝의 한계(Overhead)
파이프라이닝에는 몇 가지 한계(?), Ieal 하지 않은 점이 있다.
1.1 Stage Length 의 균일성 요구

파이프라인을 적용하려면 각 단계의 실행 시간이 동일해야 한다. 만약 한 단계가 더 오래 걸리면, 전체 파이프라인의 속도가 가장 느린 단계에 맞춰지므로, 속도 향상이 제한된다.
그러니까 단일 사이클 디자인을 N stage 로 나눈다 하더라도, 시간의 관점에선 1/N배가 되는 것 아닐 수 있다.
1.2 파이프라인 레지스터의 오버헤드
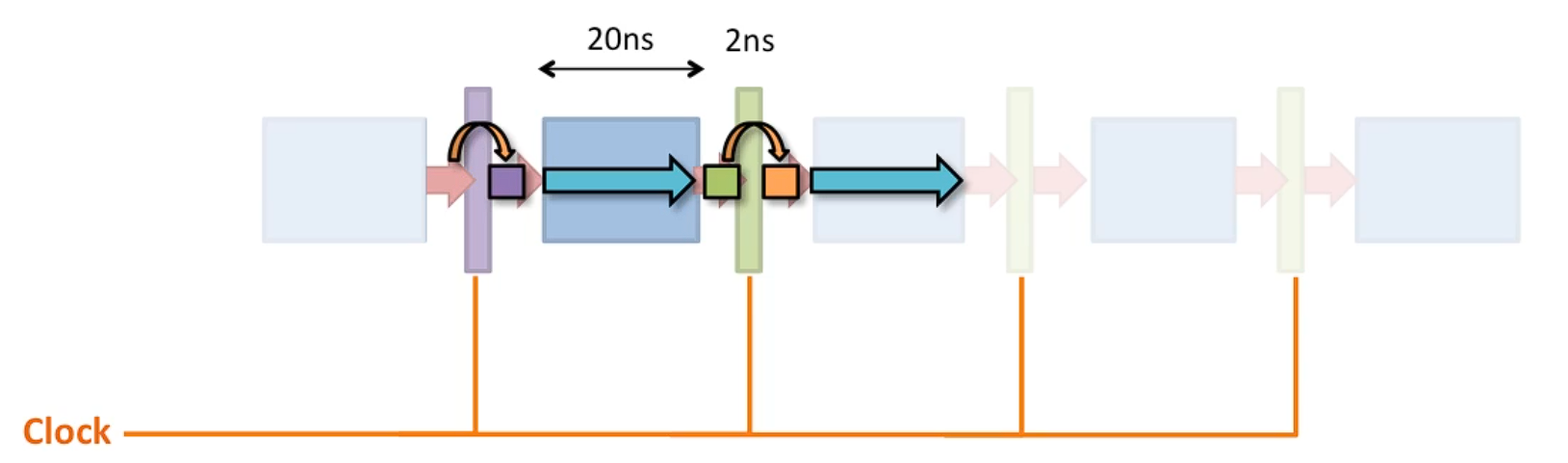
각 단계 사이에는 파이프라인 레지스터가 필요하며, 이 레지스터는 각 명령어의 상태를 저장하고, 다음 단계로 넘기는 역할을 한다. 이 과정에서 추가적인 지연이 발생하며, 이로 인해 클럭 속도가 늦어질 수 있다. 예를 들어, 각 파이프라인 단계가 20ns라면, 레지스터의 지연이 2ns일 때, 전체 클럭은 22ns로 설정해야 한다.
1.3 파이프라인이 가득 찰 때까지의 시간
파이프라이닝의 성능 향상은 파이프라인이 꽉 찬 상태에서 최대치를 발휘하지만, 초반과 마지막에는 빈 단계가 발생한다.
예를 들어, 세탁 작업에서 파이프라인이 처음으로 꽉 차기 전과 마지막 작업이 끝날 때 일부 자원이 비어 있게 된다.
그러니까 4개의 load 를 세탁한다고 해도 정확히 4배가 빨라지지는 않는다. 2.x 배 정도 빠르다.
1.4 최대한 많이 Stage 를 나누기
파이프라인을 너무 많은 단계로 나눈다는 것은, 각 단계의 조합 회로를 더욱 세분화해야 한다는 것을 의미한다.
예를 들어, ALU나 레지스터 파일을 더 작은 단계로 나누는 것은 현실적으로 어렵다. 어떻게 ALU 연산을 반으로 쪼갤 것인가? 또한,각 stage 마다 state 를 저장하기 위한 레지스터의 오버헤드가 커져 실제 연산보다 레지스터 오버헤드에 더 많은 시간과 공간이 소요될 수 있다.
결론
파이프라이닝의 효과는 자원을 최대한 활용할 수 있다는 데 있다. 세탁 예시처럼 각 단계가 유휴 상태에 머물지 않고 모두 동시에 작업을 수행하므로 효율성을 높인다(처리량, throughput을 높인다). 하지만 현실적으로는 지연과 오버헤드, 균일하지 않은 단계 길이와 같은 제약이 존재한다. 파이프라인이 가득 차고 각 단계가 균일한 시간을 가지며, 적절한 자원 관리가 이루어질 때 최대의 효율을 발휘한다.
Reference
- https://www.youtube.com/watch?v=Midapszvg7M&list=PL9b_pbvWZfKjzceHxm8aceOvNR_6icJI-&index=47
- https://www.youtube.com/watch?v=zMDCdTL1-HE&list=PL9b_pbvWZfKjzceHxm8aceOvNR_6icJI-&index=48
- https://www.youtube.com/watch?v=4erttDwaHiQ&list=PL9b_pbvWZfKjzceHxm8aceOvNR_6icJI-&index=49
- https://www.youtube.com/watch?v=24I3kUvODsI&list=PL9b_pbvWZfKjzceHxm8aceOvNR_6icJI-&index=50
- https://www.youtube.com/watch?v=ZcEwQXb8ZKI&list=PL9b_pbvWZfKjzceHxm8aceOvNR_6icJI-&index=51
'Computer Architecture > Processor' 카테고리의 다른 글
| Pipeline - Pipeline Hazard (파이프라인 해저드) 란? (0) | 2024.11.24 |
|---|---|
| Processor의 구조 - 6. Pipeline(파이프라인) 설계 (0) | 2024.11.13 |
| Processor의 구조 - 4. Decoder(디코더) (0) | 2024.11.11 |
| Processor의 구조 - 3. Clock 과 Critical Path(임계경로) (0) | 2024.11.10 |
| Processor의 구조 - 2. Control Signal 과 Data path (0) | 2024.11.09 |




댓글