- 프로세서 시리즈 모아보기 -
https://microelectronics.tistory.com/112
데이터 해저드(Data Hazards)
파이프라인 설계에서 데이터 해저드는 흔히 발생하는 문제로, 명령어 간 데이터 의존성으로 인해 프로세서의 정상적인 실행 흐름이 방해받을 수 있다.
1. 데이터 해저드란?
데이터 해저드(Data Hazards)는 특정 명령어가 이전 명령어의 결과 데이터를 필요로 하지만, 그 데이터가 아직 준비되지 않았을 때 발생한다. 파이프라인 설계의 병렬 실행 방식으로 인해 데이터 준비 타이밍이 어긋나며 이러한 문제가 발생한다.
1.1 데이터 해저드 예시
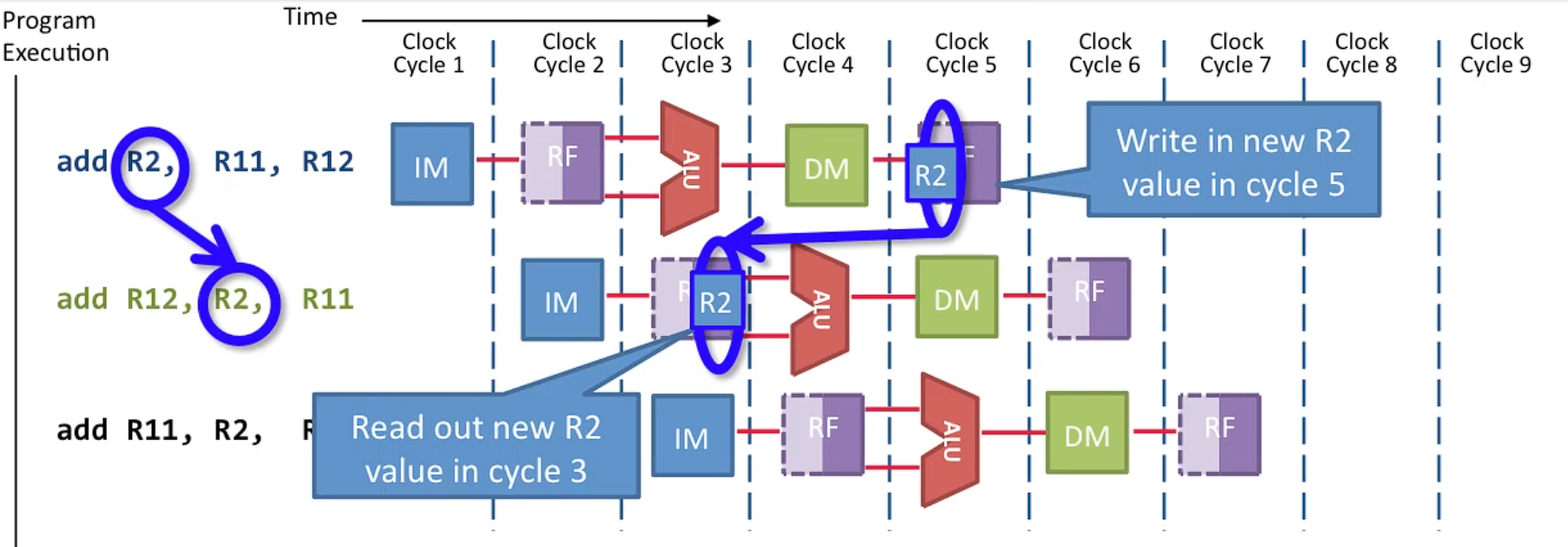
- 명령어 1(Add R1, R2, R3): R2 + R3 결과를 R1에 저장.
- 명령어 2(Add R4, R1, R5): 명령어 1의 결과인 R1을 사용.
명령어 2는 명령어 1이 R1에 값을 쓰기 전에 이를 읽으려 하므로 데이터 해저드가 발생한다.
아직 명령어 1이 끝나지 않았으므로, 값이 계산되지 않아 dumple pumpped register file 도 소용이 없다.
2. 데이터 해저드의 원인
2.1 명령어의 병렬 실행
- 파이프라인은 명령어를 병렬로 실행한다.
- 명령어가 각 단계에서 동시에 실행되므로, 데이터 의존성이 발생할 수 있다.
2.2 ISA의 약속과 파이프라인의 현실
- ISA(Instruction Set Architecture)는 명령어가 순차적으로 실행되고, 한 명령어가 완전히 완료된 후 다음 명령어가 실행된다고 약속한다.
- 하지만 파이프라인에서는 명령어가 여러 클록 사이클 동안 병렬로 실행되므로, ISA의 약속이 깨진다.
- 예: 명령어 1은 5단계 파이프라인에서 실행되는 동안 명령어 2가 이미 시작된다.
3. 데이터 해저드 해결 방법: 파이프라인 스톨
3.1 파이프라인 스톨(Stall)이란?
파이프라인 스톨은 명령어 실행을 잠시 멈춰 데이터가 준비될 때까지 기다리는 방식이다. 스톨은 파이프라인에 "버블(bubble)"을 삽입하여 문제가 되는 명령어를 지연시킨다.
3.2 스톨 적용 예시
- 명령어 1이 R1 값을 생성.
- 명령어 2가 R1 값을 필요로 함.
- 명령어 2를 한 클록 사이클 지연(스톨)하여 데이터가 준비되도록 함.
즉, bubble 을 만드려면.. register file, memory, pc 에 아무것도 쓰지 않으면 된다.
3.3 스톨의 장점과 단점
- 장점: 간단하고 안정적이다.
- 단점: 파이프라인에 버블이 삽입되어 실행 성능이 감소한다.
4. 스톨 적용 사례
1사이클 스톨

1사이클 스톨을 삽입하면 데이터 해저드가 일부 해결된다. 그러나 모든 문제를 해결하지는 못한다:
- 첫 번째 데이터 의존성(명령어 1 → 명령어 2): 여전히 충돌이 남아 있다.
- 두 번째 데이터 의존성(명령어 1 → 명령어 3): 충돌이 해결된다.
2사이클 스톨

2사이클 스톨을 적용하면 모든 데이터 의존성을 해결할 수 있다:
- 명령어 1의 결과가 명령어 2와 명령어 3에 모두 준비된다.
- 하지만 파이프라인의 성능이 더 큰 영향을 받는다. 프로그램 실행 시간이 2클록 사이클 길어진다.
Data Hazard 감지 및 해결
데이터 해저드 문제를 해결하기 위해 하드웨어나 컴파일러 수준에서 다양한 접근법이 사용된다. 이번 챕터에서는 데이터 해저드를 감지하는 방법, 하드웨어를 통해 버블을 삽입하는 방식, 그리고 컴파일러에서 No-op을 추가하는 방식의 성능 영향을 분석한다.
1. 데이터 해저드 감지 예제
1.1 예제: 레지스터 R2 의존성

다음은 데이터 해저드를 감지하는 간단한 예이다:
- 명령어 1(Subtract): R2에 결과를 저장.
- 명령어 2(And): R2 값을 소스로 사용.
- 명령어 3(Or): R2 값을 소스로 사용.
- 명령어 4(Add): R2 값을 소스로 사용.
1.2 해저드 발생 여부

- Subtract ↔ And:
- Subtract 명령어는 WB 단계에서 R2에 결과를 쓰는 중.
- And 명령어는 EX 단계에서 R2 값을 필요로 함.
→ 해저드 발생.
- Subtract ↔ Or:
- Subtract 명령어는 WB 단계에서 R2에 결과를 쓰는 중.
- Or 명령어는 EX 단계에서 R2 값을 필요로 함.
→ 해저드 발생.
- Subtract ↔ Add:
- Subtract 명령어는 WB 단계에서 R2에 결과를 쓰는 중.
- Add 명령어는 WB 단계에서 R2 값을 읽음.
→ 더블 펌핑(Double Pumping) 덕분에 해저드 없음.
2. 하드웨어를 활용한 버블 삽입

2.1 데이터 해저드 감지 로직
데이터 해저드 감지를 위해 파이프라인 레지스터 간 의존성을 하드웨어로 확인해야한다.
- 실행(EX) 단계의 소스 레지스터(Rs, Rt)를 확인.
- 메모리(MEM) 및 쓰기 완료(WB) 단계에서 생성된 데이터와 비교.
- 의존성이 발견되면 스톨(버블)을 삽입.
2.2 감지 로직의 구성
- 소스 레지스터(Rs, Rt)와 이전 단계의 목적지 레지스터(Rd)를 비교.
- 매칭이 발견되면 해저드 감지 논리가 스톨 신호를 생성.
2.3 버블 삽입 과정
버블 삽입은 특정 명령어를 지연시키고, 프로세서 상태를 변경하지 않도록 한다:
- PC(프로그램 카운터) 갱신 중지.
- 레지스터 파일에 쓰기 중지.
- 메모리 쓰기 중지.
2.4 예제

- 첫 번째 버블 삽입:
- Subtract ↔ And 해저드 해결.
- And 명령어를 지연시켜 Subtract 명령어가 결과를 준비할 시간을 제공.
- 두 번째 버블 삽입:
- Subtract ↔ Or 해저드 해결.
- Or 명령어를 지연시켜 Subtract 명령어의 결과를 활용 가능하도록 함.
- 성능 분석
- 프로그램 실행 중 7개의 클록 사이클 중 2개는 버블로 채워짐.
- 효율성: 60% (3개의 유효 명령어 실행 / 5개의 유효 클록 사이클).
3. 컴파일러 기반 No-op 삽입
3.1 No-op(No Operation) 삽입이란?

컴파일러가 미리 데이터를 기다리도록 명령어 사이에 No-op 명령어를 삽입해 해저드를 방지하는 방법이다.
- No-op 명령어 예시: Add R0, R0, R0
→ 0을 더해도 레지스터 상태에 영향을 주지 않음.
3.2 No-op 삽입의 장점과 단점
- 장점: 하드웨어 수준에서 해저드 감지가 필요 없음.
- 단점:
- 컴파일러 specific 함. (컴파일러 튜닝 필요)
- 실행 성능 저하 (No-op이 유용한 작업을 하지 않음).
4. 하드웨어 버블 vs. 컴파일러 No-op
| 접근법 | 장점 | 단점 |
| 버블 삽입 | 하드웨어가 자동으로 처리함. (하드웨어 복잡하지만 컴파일러 의존성 없음) |
하드웨어가 복잡해짐. |
| No-op 삽입 | 하드웨어가 간단해짐. | 컴파일러와 파이프라인 구조 간 의존성. |
결론
데이터 해저드는 파이프라인 설계에서 발생하는 필연적인 중요한 문제로, 명령어 간 데이터 의존성으로 인해 성능이 저하될 수 있다. 이를 해결하기 위한 방법 두가지를 게시글에서 알아보았다.
- 하드웨어 기반 버블 삽입은 유연성을 제공하지만 성능 저하를 초래한다.
- 컴파일러 기반 No-op 삽입은 하드웨어를 단순화하지만 구조 변경에 취약하다.
Reference
'Computer Architecture > Processor' 카테고리의 다른 글
| 파이프라인 실제 예시 (1) | 2024.12.13 |
|---|---|
| Pipeline - Pipeline Hazard (파이프라인 해저드) 란? (0) | 2024.11.24 |
| Processor의 구조 - 6. Pipeline(파이프라인) 설계 (0) | 2024.11.13 |
| Processor의 구조 - 5. Pipeline(파이프라인) (0) | 2024.11.12 |
| Processor의 구조 - 4. Decoder(디코더) (0) | 2024.11.11 |




댓글